FHIR Server & Interoperability Decision Theory
Decision Theory has much to do with the FHIR interoperability topic per se. Decision theory can be broadly divided into two normative decision theory & descriptive decision theory. In real time with respect to FHIR we are only talking about the normative decision theory.
The ease of accessing the data is heavily facilitated by how the decisions are made while sending the data to the FHIR server.
Having a FHIR server really simplifies the work that needs to be done on the back end, as we don’t need to build new search API etc. But there is a saying “Things that are easy to implement are often difficult maintain and things that are easy to maintain are often difficult to implement“. This applies for using FHIR server too.
Over a period of 4 years I have worked on FHIR and I faced challenges which I’ve summarized here. These are the things which you should keep in mind when you don’t really know who is going to consume data from your FHIR server.
First Decision – (Patient ID) – Basic Challenge:
Often times people say we need to send the patient resource to FHIR server simply without understanding the impact of it. This is a big problem especially if your having the patient resource as base resource (meaning your application depends on patient resource to fetch any other resources), basically when all other resources depends on the existence of patient resource.
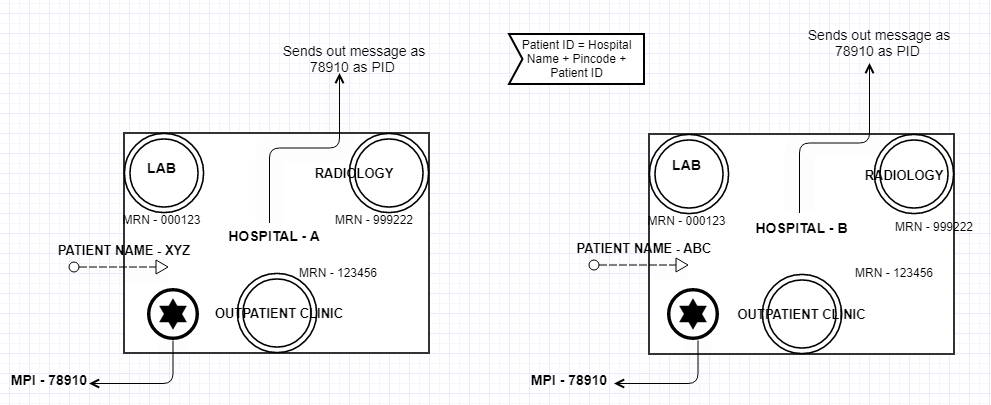
It is very possible to have same patient id generated from different hospital. In this case you need to make sure your patient ID is a combination of the hospital name + area code or the pin code and patient ID generated by the hospital. Why we need to do this?. With in each big hospital each sections may have different software as shown in the picture below and the hospital need a special software called PIX manager (a software that will uniquely identify the patient id distributed across multiple section of a hospital and provide a unique ID, this id is called Master Patient Index). It is certainly possible that two different hospitals may send same Identifier for two different patients. You can read a lot of related terminologies from here.
Whenever the patient resource is sent we must send the associated organization (there can be multiple other interpretations for organization as per FHIR) to it. Meaning the hospital the patient belonged to. Otherwise its impossible to know which patient is from which hospital. A patient resource can be a simple resource but it handles hell a lot of problem in the real world.
One recent challenge I’ve faced – My client wanted to do a AI/ML based research on Covid-19. In a hurry he insisted to build a patient resource, after the first phase of the app is released the client’s research team mentioned that almost 50% of the data we received positive from a particular hospital were patient belonging to Asian Race. Now the Race of patient is not must in patient resource. It didn’t mandate it. But I’ve fortunately added the race as an extension and stored it. In fact I created a search parameter for that FHIR element. Imagine what would have happened if I didn’t capture the race part here?
This gives a very big question on the FHIR standard itself. How can a group of people sit together & uniformly decide what is important data in a resource?. What is not needed for them can be much needed for me (for example Race of patient as mentioned above). But, If there is a liberty to add whatever I want then why it is called a standard?. Remember HL7v2 difficulty? This is like asking Universal Basic Pay for all laborer’s across the globe. Except the part that the meaning of basic is different for different countries. Bread is basic in USA, Rice in basic in India. The same reason why not all country have same currency. The inflation rates are different. FHIR solves this by providing profiles, which is another headache. I can write serious of problem with profiles itself.
I have many experience in past two years where clients implement FHIR server and call me to ask “we have many patient in our database but how to know which organization they belong to”. All I see a lot of orphan records of patients without knowing their source organization. Answer is simple before implementing, hire a person who knows stuff.
Second Decision – (re-processing mechanism) – Know what your searching for:
Before sending the resources to FHIR server you must make sure what you’re searching for (identify the search parameters before hand). In reality 90% of time we will never know what we need to search for until and unless a specific use case comes to picture.
Most of the clients whom I’ve worked, will wake up everyday and say “I need one more data and how should I query?”. How to solve this problem?, You can’t solve this problem. Being a pragmatist in the world of interoperability and FHIR, I would say client’s requirement always evolve. They evolve everyday. If I’m good at what I’m doing, I must find a better way to facilitate his requirement.
Always be prepared to handle such scenarios. For instance, if your creating a new extension and setting a search parameter resource for that extension, you can do it in the FHIR server using the search parameter resource. But problem is this search parameter will not work for the resources you have sent before or existing in the FHIR server already. So, in this case you need to re-process the entire messages again. So, make sure your message re-processing mechanism is very robust and well automated. Always archive the data properly. Archiving is useless if you don’t have a proper mechanism to reprocess. So, find a best way to reprocess/re-try messages.
A FHIR server will have endpoint, a URL to which you send your resources to. From last 5 years of IT experience I have understood that if your sending a data to an endpoint, you must assume that an endpoint is always at 100% risk. Meaning one your endpoint can go down anytime. You have to get a better queuing mechanism. A better way to organize the data so that whenever your FHIR server is up and running it should execute.
This is just one example. It might not be a search parameter. It can be a completely different use case as well. But the point here is, we need to have a clear message reprocessing mechanism.
Inpatient & Outpatients are not the same:
You need to identify a mechanism that differentiates or distinguishes or treat inpatients and outpatients hospitals and segregate them wisely. But why do we do that?. If its not a business need?
Let us take any FHIR resource like EOB (Explanation OF Benefit) this resource is referring encounter resource. Of course it’s optional. It is not mandatory that EOB must refer an encounter. But from the Payor side, an explanation of benefit resource is directly associated with an visit. A patient visiting the physician is directly connected with the visiting charge. In case of ambulatory a patient visiting doctor is simple formulae. Every visit is a encounter and every time the patient visits a doctor the emr/pm system triggers a ADT message with changes in the PV1 segment.
But this is not the same in Inpatient cases. For a patient admitted in the hospital for 10 days every time the nurse comes to observe the vital becomes a patient status the emr will trigger a message. Every time a doctor changes the medicine the emr will trigger the message. So what is encounter here?. unlike the ambulatory process not every message is expected to have unique visit id. In that case a patient can have multiple visit id for his stay. How can we uniquely identify the encounter for inpatient?. The best way to handle encounter is to see this as episode of care rather than encounter itself.
The question still exists. So, if your end user is creating an encounter specific platform make sure you differentiate encounter coming from the ambulatory clinic and inpatient hospitals. In this case profiles might help you. Create different profile for ambulatory and inpatient hospitals. Change the SD accordingly.