How important is Synthea for Interoperability
I really believe this blog will help people to test their interface engine logic pretty efficiently.
It is very sad that the interface engines testing were not very clearly defined. Testing a unit of code is pretty difficult for any interface engines that are existing in market.
Testing samples:
Imagine I’ve written a piece of code in JAVA or .NET. I can run a testing logic on that to see if the code is not breaking or not. I can write a Junit test cases to see if the code behaves as expected in the real time scenarios.The important word to notice here is the “real time” scenario. Quite often the popular interface engines in the market end in the phase where its difficult to test the unit of code in the real time scenario.
The biggest challenge the interoperability faces is “testing” conversion of the data from one format to another needs to be robust. For that robust testing is needed. Unless you know what one system send to test the data the developer or manager will be coding blindly. Mapping of data needs actual data.
This is where Synthea™ comes into picture. It’s main aim as i understand is to provide patient generator that models the medical history of synthetic patients You can know more about Synthea™ in detail here
How does it work?
Imagine you are converting a CCDA to FHIR or the vice versa. You need a sample of data with certain fields and values. What synthea™ provides is, it gives you all the data in the format you need for testing the interface.
You don’t need to search the online sources for the list of CCDA and get few samples but the samples you get might be outdated, might not be generated out of the real world scenario. But Synthea™ provides you the real world look alike data for testing.
It is also having multiple modules here. So, you can refer more here at this level. It is really good that even COVID-19 support exist for this https://github.com/synthetichealth/synthea/wiki/Module-Gallery
Synthea™ data for testing is very cozy that we need to change everything in their properties file. In the src/main/resources/synthea.properties has every customizing options. By default Synthea™ don’t provide anything we need to enable them in the properties file as shown below
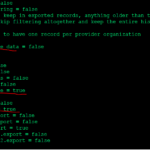
The customizing parameters includes Adherence, death by loss of care, VitalSigns, Alcoholism, Smoking, insurance companies, Provider maximum_search_distance, weights, education, income etc.
How to use?
It is opensource. You need to have grandle installed in your system. If your using the windows just download the grandle complete package and put the bin path in your environment variables. C:\Gradle\gradle-6.5.1\bin. One pre-requisite here is that you need to make sure that JAVA_HOME is set properly.
Verify if the gradle is installed in your system using “gradle -v”. Now enable the setup in the properties file as mentioned above and run the command — for instance “run_synthea -p 30” P is the population size and 30 is the count.
I think one of the important feature of using Synthea is that it not only use CCDA and FHIR data. It also provides CSV format of data. You can check what it does here. Remember most of the real time EMR exports the CSV data. This CSV data export is definitely worth using them as a standard for creating a model interface.
Although it is highly unlikely that all EMR will export data in the same format as the Synthea provides. But certainly a request can be made to the EMR team to provide data in the reference model that Synthea provides.
In other words, in the world of Ruby language there is something called Faker Gem. This library provides a lot of meaningful examples that looks like the real world in fact there is a Java library equivalent for that. I have tried it and used it to see how it works and it worked brilliantly. You can refer that here